
Horizontal scaling is amazing when it comes to scaling software in the cloud and with the current state of cloud services, it is really easy to scale solutions horizontally. Kubernetes (aka, k8s) has made it really easy to manage containers and scale a software solution
The name Kubernetes originates from Greek, meaning helmsman or pilot. K8s as an abbreviation results from counting the eight letters between the “K” and the “s”
In this article, I am going to talk about the important components of a Kubernetes cluster
👉 Before containers
Earlier before 2012 a lot of organizations would use virtual machines to scale their solutions horizontally. So ideally they would deploy their code on a virtual machine like VMWare, AWS EC2, or Google Compute Engine, etc., and scale their solutions using the platform-provided autoscaling solutions. So whenever there is a need for more computing power the autoscaling will create a new VM instance automatically to serve user’s requests
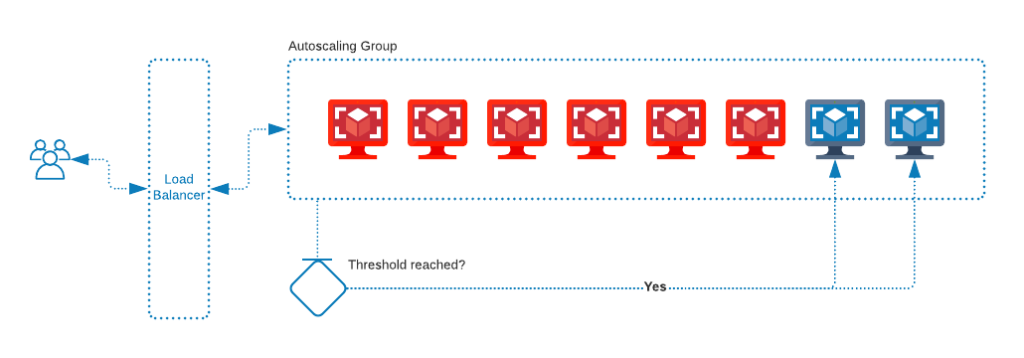
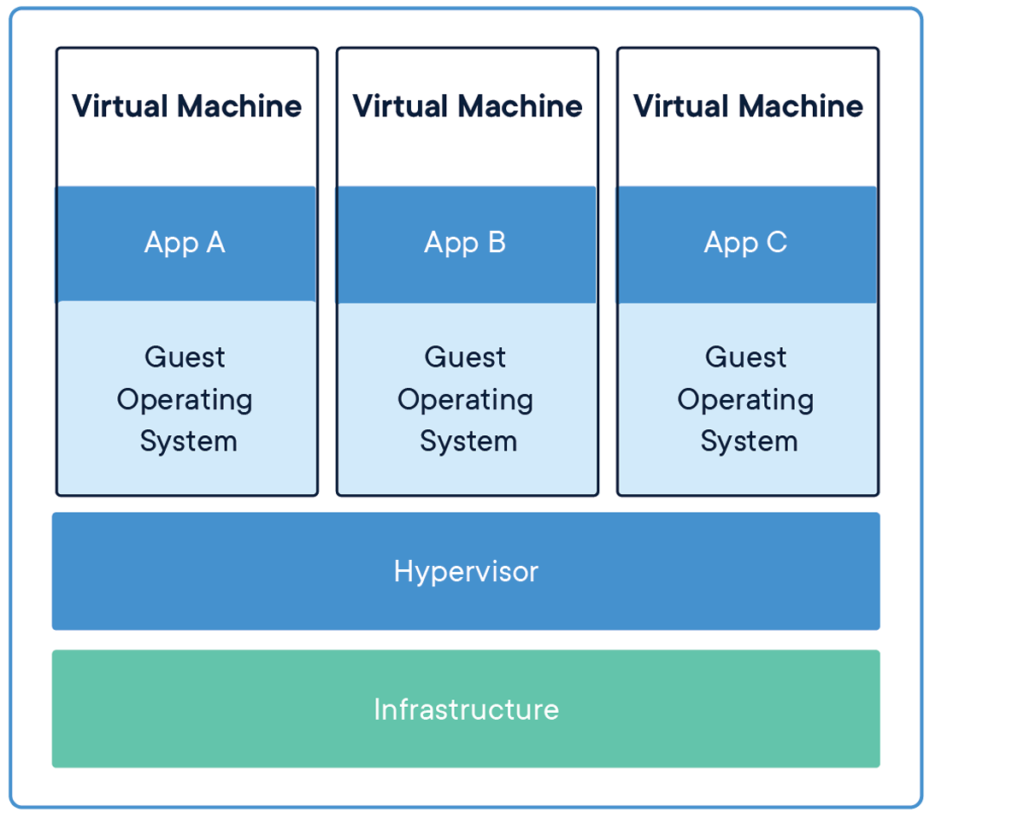
The virtual machines are not lightweight and come with their own burdens since you will be running a fully-fledged operating system on them, also it is not easy to manage
👉 After containers
A container can be explained as
a standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another. A Docker container image is a lightweight, standalone, executable package of software that includes everything needed to run an application: code, runtime, system tools, system libraries and settings
What is a container? – https://www.docker.com/resources/what-container
Unlike VMs, the containers are lightweight and easily manageable
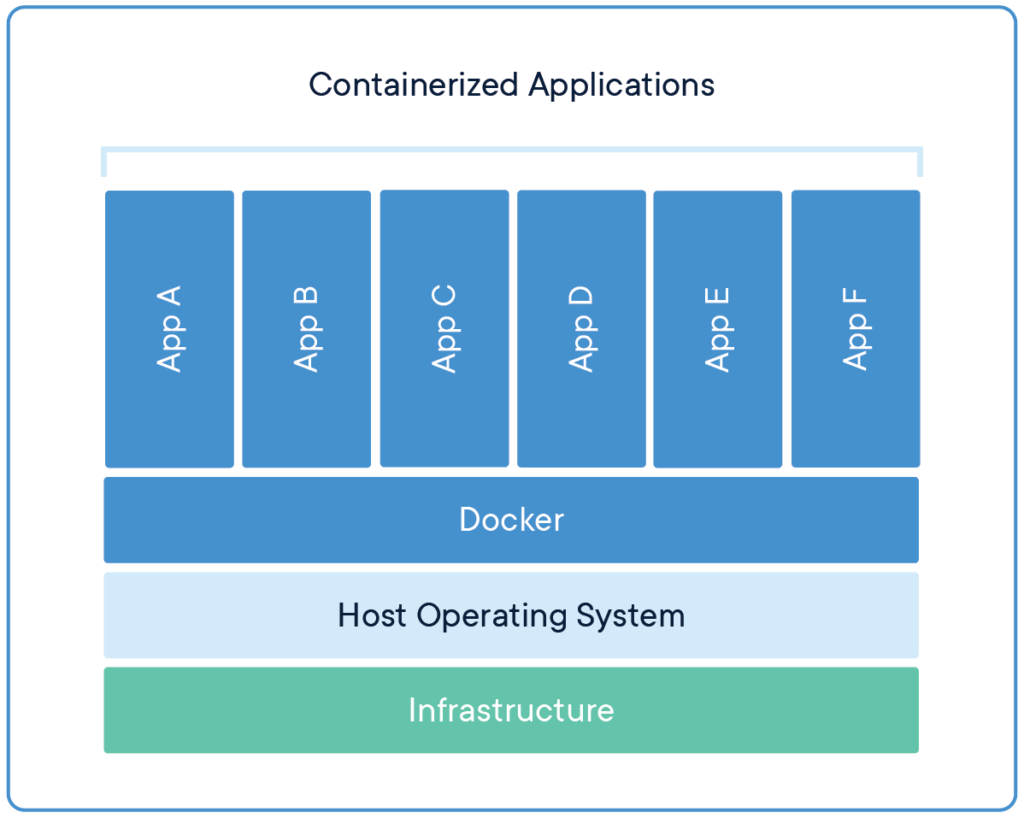
So we can run our apps on containers instead of VMs, that part is clear. But how do we manage other things like deployment, scaling, security, service discovery, load balancing, etc? And that’s exactly where Kubernetes comes in.
👉 Kubernetes and its components
Kubernetes is open-source software for scaling and managing containerized workloads and services. The k8s cluster can be communicated with the help of a deployment.
What is a deployment you ask? well, the deployment usually is a YAML file that consists of instructions to manipulate the Kubernetes cluster objects. Everything inside a k8s cluster is designed to be accessible as an object.
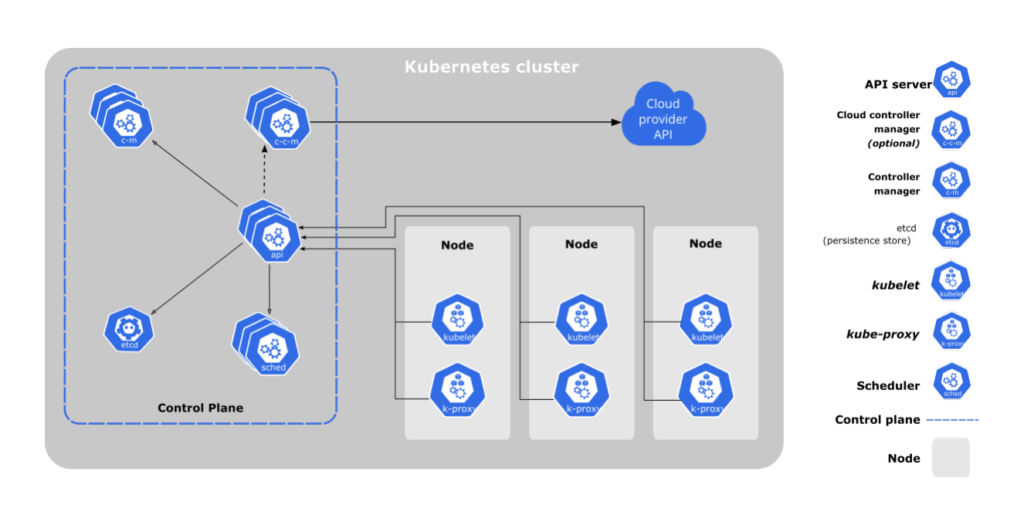
As described in the above diagram, a k8s cluster can be divided into two primary sections, worker node, and a control plane. Let’s talk about it
worker node can be defined as the part of the cluster which actually runs the containers (aka pods in a k8s), every cluster must have at least 1 node. Various components inside a pod are kubelet, kube-proxy, and the container runtime
kubelet is an agent that runs on every node. It makes sure that the node is running a pod with the given podspec. A podspec is a YAML file describing the pod.
kube-proxy is a network proxy that runs on each node in your cluster. It makes sure that the pod is accessible by the outer world by defining network rules.
container runtime is the software that is responsible for running the containers. k8s supports various runtimes like docker, containerd, CRI-O. Docker being the one that is widely used by developers
control-plane manages the worker nodes and the pods in the cluster. In a production environment, the control plane usually runs across multiple computers and a cluster usually runs multiple nodes, providing fault tolerance and high availability. Various components inside a control plane are kube-apiserver, etcd, kube-scheduler, kube-controller-manager, and the cloud-controller-manager
kube-apiserver exposes Kubernetes APIs to the outside world for communications. The API server is the frontend for the Kubernetes control plane. It is designed to scale horizontally, meaning several instances of API servers could be deployed to balance traffic to k8s APIs.
etcd is a consistent and highly available key-value store used as Kubernetes’ backing store for all cluster data. It is not good practice to store app-specific data in etcd. It is only used by k8s to store the configuration data, its state, and its metadata, etc.
kube-scheduler watches for newly created pods with no assigned nodes and selects a node for them to run on. Factors taken into account for scheduling decisions include: individual and collective resource requirements, hardware/software/policy constraints, affinity and anti-affinity specifications, data locality, inter-workload interference, and deadlines
kube-controller-manager runs controller processes. A controller is a separate process, but to reduce complexity, they are all compiled into a single binary and run in a single process. Examples of controllers may include node, job, endpoint, service account and token controllers.
cloud-controller-manager lets you link your cluster into your cloud provider’s API and separates out the components that interact with that cloud platform from components that only interact with your cluster. This component is not really that important because, for the most part, you will be using a managed Kubernetes cluster that does the job for you. AWS Kubernetes implementation is called EKS and Google’s implementation is called GKE.
These are the important components in a k8s cluster, but I would also like to make it clear that there is so much more to k8s than what we just understood. I will be writing more articles on k8s in the coming future. I love using k8s in my projects and can’t wait to share what I learn in the process. Until next time.
✌️❤️
Leave a Reply